 时刻新闻
时刻新闻
本报记者 左志红 尹琨
《出版业“十四五”时期发展规划》明确将出版业科技与标准创新示范项目列入出版融合发展的重点工程。今年,国家新闻出版署将在2021年试点工作基础上,深入实施出版业科技与标准创新示范项目。
2021年出版业科技与标准创新示范项目试点工作共评选发布科技与标准创新成果13项、应用示范单位14家,取得良好成效。参与2021年示范项目评审的专家在接受《中国新闻出版广电报》记者采访时表示,通过2021年的试点工作,可以看到,人工智能、大数据、云计算、科学可视化、AR/VR、区块链等技术被广泛应用于出版、印刷、发行、版权等领域,展现了出版全产业链拥抱和应用新技术的创新图景,一批聚焦前沿、专精特新、支撑主业、放大效能的项目和技术,构成了当前我国出版业科技创新应用的第一梯队。
创新主体架构更加清晰完备
为更好地发挥科技与标准在出版高质量发展中的支撑作用,加强示范引领,促进成果转化,2021年5月,国家新闻出版署印发《关于开展出版业科技与标准创新示范项目试点工作的通知》,面向国内出版单位、高等院校、科研院所、技术企业,以及国家新闻出版署确定的出版业科技与标准重点实验室,征集评选一批技术研发、标准研制等方面的优秀成果,以及在科技与标准应用方面具有示范作用的单位。
《通知》印发后,共有131个项目申报,覆盖中央在京及24个省(区、市)的120家单位,其中,科技类项目申报113项,标准类项目申报18项。经过评审,最终确定10项科技创新成果、10家科技应用示范单位,以及3项标准创新成果、4家标准应用示范单位入选2021年出版业科技与标准创新示范项目。
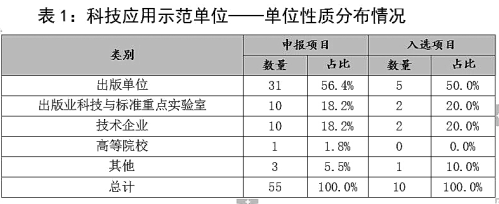
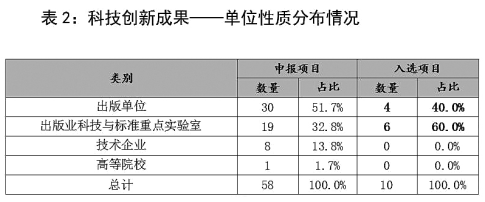
从申报的科技应用示范单位看,56.4%为出版单位,18.2%为出版业科技与标准重点实验室,18.2%为技术企业,7.3%为高等院校和其他类型的申报主体(见表1)。入选的10家科技应用示范单位中,出版单位占了5席,重点实验室和技术企业各2席,其他类型的申报主体1席(见表1)。而入选的10项科技创新成果则均来自出版单位和重点实验室(见表2)。
项目评审专家表示,从上述分析可见,以出版单位为主体、实验室为重点、科研院所和技术企业为辅助的出版业科技创新主体架构更加清晰完备。
全产业链条应用前沿技术
“我们发现,入选的科技应用示范单位既保持对前沿技术的敏感性,又坚持问题导向,将技术赋能主业发展,创造深具出版业特色的科技应用新生态。”项目评审专家说。
从应用的相关核心技术来看,在入选的示范单位中,应用大数据技术的单位占比达到90%,应用云计算技术的单位占比达到了70%;在入选的科技创新成果中,人工智能、大数据、云计算、科学可视化、语义识别、版权保护、数据标引、AR/VR、区块链等新技术更是得到了较为广泛和深入的实际应用,其中,人工智能技术应用占比达到90%。
在通用技术应用方面,一些项目已能够充分利用人工智能技术的数据感知、采集、存储、处理、分析、可视化等,提取内容数据的价值,汇聚各类数据与资源,为主业赋值赋智;在出版业特色技术应用方面,一些项目通过引入前沿科技,在中文字库生成、古籍整理等方面创新手段,创造出一批出版业特色新技术。
项目评审专家表示,这充分体现了出版业拥抱前沿技术,从需求出发,在内容生产、印刷发行、数字内容资源管理、知识服务、版权保护等全产业链条上的前沿技术应用场景。
标准化创新有待进一步加强
近年来,出版新技术标准规范体系建设已初见成效,覆盖出版产业链各环节的标准体系已初步形成,相关国际标准、国家标准、行业标准、团体标准、企业标准、工程标准的制定工作都在有序推进,标准在出版业的示范、驱动、规范和引领作用日益凸显。
2021年,新闻出版领域共发布国家标准12项、行业标准16项,涵盖知识服务、标识符管理、数据质量检测、数据交换、智能印刷等方面,内容与出版业数字化、智能化密切相关。团体标准蓬勃发展,中国音像与数字出版协会团体标准化技术委员会紧紧围绕行业急需开展标准研制,发布网络游戏、数字化教育资源相关团体标准5项。一批实力较强的出版企业在专业领域研制了相关的企业技术标准,为推进企业规范管理、技术进步、效益提升提供了有力支撑。全国新闻出版标准化技术委员会还评选设立多家专业数字内容资源知识服务模式企业标准示范单位和新闻出版标准示范基地,发挥模范企业的引领作用。
“尽管出版业标准体系建设正日趋完善,但出版业相关标准的创新应用工作,因对标准研发和应用平台的技术基础、团队能力、投入周期等要求较高,加之近年来信息技术发展突飞猛进,出版业科技环境和市场需求变化加剧,稳定有效的标准类创新成果还有待进一步提升。出版单位应用标准的意识还有待进一步加强。”项目评审专家表示。
2021年度标准类申报项目不多,入选的3项标准创新成果和4家应用示范单位,均属于聚焦垂直领域知识服务标准、智能出版标准、数字教材标准以及专业内容数字阅读技术标准领域的项目和单位,通过标准应用和研发,在提高出版业产品和服务质量、促进转型升级和融合发展方面成效明显。
该专家表示,期待通过示范引领,引导行业内技术基础坚实、新业务新产品聚集的企业、平台和科研组织,进一步加大科研投入,多维度、多层次开展出版业新标准的研发和应用。
出版科技创新需持续加大投入
“从报告可见,出版业科技创新需要持续加大投入,转型升级融合发展进程中的科技创新战略地位仍有待进一步强化。”项目评审专家表示。
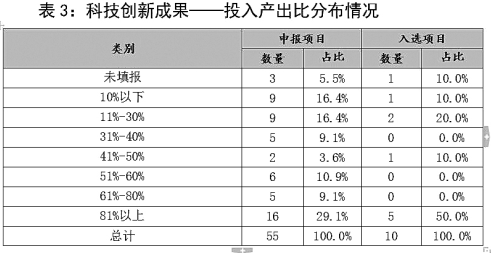
统计显示,本年度申报的113项科技类项目中,累计投入在1000万元以下的占58.4%,仅有15.93%的项目累计投入在5000万元以上;最终入选的20项科技类项目中,累计投入在5000万元以上的则占到了35%。申报的科技创新成果中,46.6%的项目累计收入在100万元以下,投入产出比在30%以下的达58.6%(见表3)。可见,科技创新投入力度和投入产出效益的提升都迫在眉睫,转化能力和经济效益有待进一步提升。
在113项科技类申报项目中,仅有10.62%的申报主体在基础申报材料中,明确提及“科技应用创新规划”或“将科技应用创新作为本单位一把手工程”。如清华大学出版社制定并发布了《“十四五”数字出版发展规划》,北京师范大学出版集团规划了“数字出版工作小组(松散组织)—数字出版中心(独立部门)—全资公司(独立法人)—股份公司—股份公司+全资公司+工作组”的组织架构进化之路。
14.2%的科技类项目拥有的自主知识产权数量(包括商标、专利、软件著作权等)在50项以上,但是仍有48.7%的科技应用类项目拥有的自主知识产权数量为5项以下,客观反映了尽管已有部分单位拥有了较强的自主研发实力,但出版业整体科技创新研发实力仍有较大的提升空间,科技与标准在出版高质量发展中的支撑作用有待进一步增强。
标准创新成果
1.新闻出版知识服务系列国家标准
新闻出版知识服务系列国家标准是在新闻出版行业开展的“专业数字内容资源知识服务模式试点工作”的基础上,由全国新闻出版标准化技术委员会组织数十家在知识服务领域具有领先经验的出版业龙头企业共同研制的,是出版业应用新技术、探索新模式的具体实践和经验总结。该系列标准包括7项:《新闻出版 知识服务 知识资源建设与服务工作指南》《新闻出版 知识服务 知识资源建设与服务基础术语》《新闻出版 知识服务 知识资源通用类型》《新闻出版 知识服务 知识关联通用规则》《新闻出版 知识服务 主题分类词表编制》《新闻出版 知识服务 知识元描述》《新闻出版 知识服务 知识单元描述》(标准号:GB/T 38376-2019至GB/T 38382-2019),对促进新技术在出版业的应用转化、深化出版业融合发展具有积极作用。
2.《有声读物》行业标准
该行业标准规范了术语和定义,对录制流程、录制与发布、平台的技术和服务以及评测的流程、指标、条件、计分方法等提出了规范要求,填补了有声出版物加工制作领域的标准空白。标准推广使用以来,已得到近百家有声读物制作出版机构和听书平台采用执行,行业使用覆盖率超过80%。标准已用于有声读物的制作项目数量1.2万多(项)个,累计服务听书平台B端上百家有声读物内容提供商和听书平台3000多万个(次)C端用户。该标准对于保障有声读物的内容质量、提高有声读物的阅读体验、强化行业规划和管理具有重要意义。
3.《数字版权唯一标识符》行业标准
该行业标准是DCI体系的基础性核心标准,规定了DCI的编码结构、分配规则和管理机制。基于该标准,对信息内容的版权权属关系进行标识,实现信息内容的创作、传播及使用行为与其主体的一一对应标识,建立起以公共服务信用与区块链技术信用共同强化的、可信赖可查验的权、责、利一一对应关联体系。数字内容有了DCI这一“版权身份证”,在权属确认、授权结算、维权保护等方面的应用扩展也就有了无限可能。该行业标准在多个互联网内容产业垂直领域典型平台持续开展标准示范应用,累计完成基于DCI标准的数字作品版权登记100余万件。目前,DCI国家标准已由国家标准化管理委员会正式立项。截至2021年11月,基于DCI标准实施已为170余万作品分配了DCI。
科技创新成果
1.出版资源语义组织与智能阅读关键理论与技术(语义出版与知识服务重点实验室)
本项目聚焦出版领域核心的内容资源,借助深度学习、自然语言处理、知识图谱、虚拟现实等相关的先进智能技术,对多源异构多模态的资源进行数字化、数据化、语义化、智能化处理,形成了一套智慧数据与语义出版框架流程及标注规范,用于对科技文献、文化遗产数据等各类出版资源进行语义组织和内容重组。基于以上研究,本项目开发设计了不同文本载体语义结构的自动解析与抽取、自动文本摘要、语义查询及个性化推荐、多源图文融合等智能化算法,针对智慧数据与语义出版框架流程及标注规范实施过程中面临的关键问题,形成一批自主知识产权的核心技术。
2.DCI体系版权服务基础设施1.0(DCI技术研究与应用联合实验室)
该设施1.0以我国自主创新的数字版权唯一标识符(DCI)标准为引领,以区块链、云计算、大数据、人工智能等先进技术集成应用为支撑,以规范高效的版权公共服务体系与机制为保障,从网络信息内容的版权标识入手,通过打造互联网版权基础设施,开放版权权属确认、授权结算、维权保护等版权服务核心能力,进一步构建互联网版权产业新生态,以推动解决长期困扰我国版权产业高质量发展的权属确认不清、授权交易不畅和维权保护困难等关键性瓶颈问题。自2021年8月上线以来,该设施1.0已为65万余件作品分配了DCI,同时,中国版权保护中心已着手规划建设DCI体系版权服务基础设施2.0。
3.凤凰智能校对系统(江苏凤凰报刊出版传媒有限公司)
该系统用于专业出版领域的文本纠错和内容审查,能够辅助文字工作者检查、纠正文稿中存在的各类字词语法、知识事实、内容格式错误,同时审查其导向正确性,保障出版物意识形态安全。系统基于人工智能技术开发,创新性地在计算机校对中融合了自然语言处理技术与汉语言语法理论,在百亿语料的支撑训练下,能够更准确、更高效地识别出文稿中未经过事先预设的随机错误、语法错误以及政治类差错。该系统自2019年上线以来,已发展机构用户近6000家,覆盖用户30万人,累计校对各类文稿26亿字,广泛应用于政府机关、新闻出版、文化传媒、教育科研等多个行业领域。
4.古籍智能整理出版工具集〔古联(北京)数字传媒科技有限公司〕
工具集研发的主要目标是以古籍整理和古籍数字化的基础工作为线索,再造线上工作流程,力求覆盖古籍整理的多种业务场景,解决或改善传统流程中大量消耗人力资源、时间成本和物料的问题。如探索基于机器学习的古籍OCR(光学字符识别)技术,针对版刻、稿钞、铅印等多版本古籍,进行图像智能识别算法训练,研究面向中文古籍的高效OCR识别模型,形成支持专业个人用户、小团队作业的敏捷型智能OCR平台。用户可灵活调用OCR算法、繁简转换、自动标点、命名实体识别、文本校勘、古籍引文校对等古籍整理和编辑加工模块,减轻专家、编辑在各环节的工作负担,从而提高古籍整理工作的效率。
5.“古谱今译”融合出版技术(上海音乐出版社有限公司)
该技术已实现减字谱和工尺谱的数字化标准录入,将字型、输入法等具体问题进行应用规范,开发了一套常用的典型性减字谱和工尺谱字库,实现了初步的减字谱和工尺谱数字化进程。已有成果:符合UNICODE国际标准古琴减字谱数字化字库2套(共计5万余字符)、古琴减字谱数字化输入法2套、工尺谱3套、工尺谱输入法1套、排版软件1套。在新技术的支持下,上音社通过版权购买、资源抢救、内容修复、数据存储、音视频配等专业的融合出版手段,形成纸、电、声、像一体化,具有时代性的“古谱今译”融媒体出版品牌,打造全国首个“中国传统古谱打谱中心”。
6.个性化中文字库自动生成技术(新闻出版智能媒体技术重点实验室)
该技术研究团队在大规模中文字库自动生成、高质量矢量字形合成、字形纹理特效风格迁移等方面取得重要进展,多方位突破中文字库制作生成的技术瓶颈,研发成功中文字库辅助设计与自动生成相关系统,显著提升各类字库的制作效率。2018年,研发的中文字库辅助设计与自动生成技术通过技术转让方式在企业投入使用,对外开放的字库制作平台总注册用户超过150万,创建的个人字库超过200万套,手写体中文字库自动生成系统已经接入华为、金山WPS等移动平台;开发的相关中文字库产品在腾讯、华为等主流IT企业的产品中得到广泛使用。
7.基于物联网与人工智能技术的实体书店关键装备(新闻出版领域关键技术研发及应用综合实验室)
该装备包括智能书架、移动书架机器人、图书出入库机器人、智能阅读台等硬件设备,运用物联网技术进行图书管理,实现图书的在架位置识别、自动盘点、防盗和自助借还、无人售卖等功能,在此基础上分析读者对图书的阅读次数、时长等信息,进而分析不同图书的热点程度,最终实现书店整个环节的无人化、信息化、智能化。基于该装备的智慧书城作为实体书店管理和图书销售的补充,可适应公众的购物行为习惯,并搭建行业大数据平台,为书店经营者提供运营策略支持,为出版单位提供选题策划的量化依据,为主管部门决策提供行业级的数据分析。
8.基于智能技术的教育资源数据中台建设项目(高等教育出版社有限公司)
高等教育出版社统一资源中心,采用数据中台和业务中台的双中台架构,借助大数据、机器学习技术,分析和挖掘数据价值,为数据赋值,为业务赋智。主要创新成果包括建立用户中心,实现用户统一认证服务;制定数据规范,实现数据模型的规范和统一;创新数据同步机制,实现业务多源数据的实时采集;探索智能审核技术,有效提升内容安全保障;深入挖掘数据价值,优化内容策划与生产;实现实时数据统计,数据可视化显示。统一资源中心已完成内容管理平台、图书二维码平台、智慧职教、MOOC学习平台、中国大学生在线等八大平台的统一管理,汇聚各类资源500余万条,已为近2000万用户提供在线服务。
9.面向出版领域的信息抽取与组织关键技术(CNONIX国家标准应用与推广实验室)
该技术旨在通过采用深度学习方法,利用自然语言处理中信息抽取技术,解决出版业图书细化分类和基于图书内容的搜索等问题。目前,成果主要应用有:联盟成员单位新疆新华书店的新疆民族文字出版发行大数据工程项目,在项目中开展了基于图书内容的信息抽取研究,使用了包含10余万图书信息的中文图书分类数据集作为语料库对模型进行训练,对图书内容简介进行语义分析,实现了图书标签自动生成、图书智能推荐等功能。国家出版发行信息公共服务平台,采用信息抽取技术,为图书自动生成标签,为图书精细化分析提供技术保障等。
10.印刷品机器视觉的颜色检测关键技术(智能与绿色柔版印刷重点实验室)
本项目研发出基于机器视觉的印刷色彩检测系统,能够实现对印刷装置印刷出的印刷产品进行色彩质量快速高效检测,可以将图像采集设备的要求以及印刷品检测色条的参数要求大大降低,直接根据色度值与标准色度值来评价印刷产品的质量,快速高效。
来源:中国新闻出版广电报/网
作者:左志红 尹琨
编辑:莫夏倩